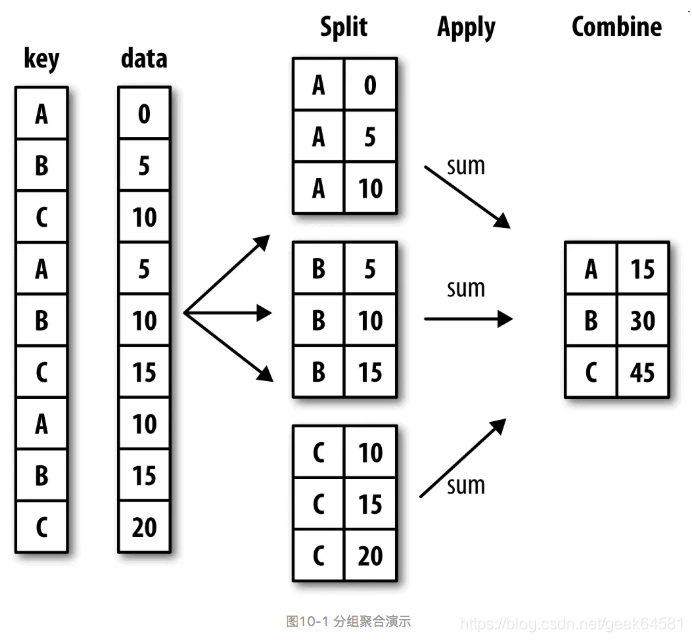
group = df.groupby('gender') list(group) # 查看详细数据 group.groups # 查看数据(字典的形式)
# 分组后的名字是: F M # 改组后的数据是: 每个index对应的值
for name ,data in group: #遍历对象 print(name)
for name ,data in group: print(data) # 详细的数据
for name ,data in group: print(name, data) for name ,data in group: f_mean = data['age'].mean() # 可以求出来年龄的平均值 f_max = data['age'].max() # 年龄的最大值 print(name, f_mean,f_max)
多列分组
1 2 3 4 5 6
group = df.groupby(['country','gender']) # 根据country完以后再对gender分组
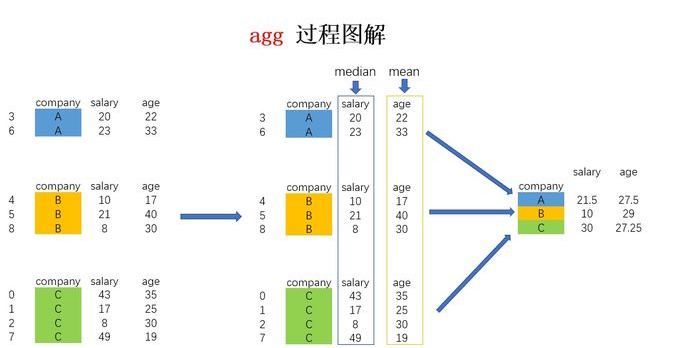
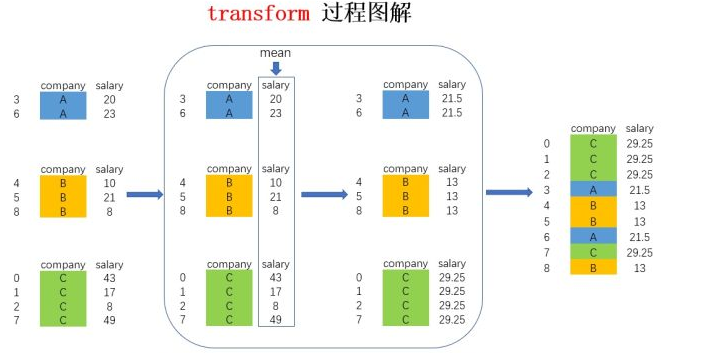
data=pd.DataFrame({ "company":[company[x] for x in np.random.randint(0,len(company),10)], "salary":np.random.randint(5,50,10), "age":np.random.randint(15,50,10) } ) data
data=pd.DataFrame({ "company":[company[x] for x in np.random.randint(0,len(company),10)], "salary":np.random.randint(5,50,10), "age":np.random.randint(15,50,10) } )
data=pd.DataFrame({ "company":[company[x] for x in np.random.randint(0,len(company),10)], "salary":np.random.randint(5,50,10), "age":np.random.randint(15,50,10) } ) ------------------ data.groupby('company')['age'].mean() ---------------------